|
|

|

|
| e-Pub |
Section: New Results
Tracking and Video Representation
Participants : Ratnesh Kumar, Guillaume Charpiat, Monique Thonnat.
keywords: Fibers, Graph Partitioning, Message Passing, Iterative Conditional Modes, Video Segmentation, Video Inpainting
Multiple Object Tracking The objective is to find trajectories of objects (belonging to a particular category) in a video. To find possible occupancy locations, an object detector is applied to all frames of a video, yielding bounding boxes. Detectors are not perfect and may provide false detections; they may also miss objects sometimes. We build a graph of all detections, and aim at partitioning the graph into object trajectories. Edges in the graph encode factors between detections, based on the following :
-
Number of common point tracks between bounding boxes (the tracks are obtained from an optical-flow-based point tracker)
-
Global appearance similarity (based on the pixel colors inside the bounding boxes)
-
Trajectory straightness : for three bounding boxes at different frames, we compute the Laplacian (centered at the middle frame) of the centroids of the boxes.
-
Repulsive constraint : Two detections in a same frame cannot belong to the same trajectory.
We compute the partitions by using sequential tree re-weighted message passing (TRW-S). To avoid local minima, we use a label flipper motivated from the Iterative Conditional Modes algorithm.
We apply our approach to typical surveillance videos where object of interest are humans. Comparative quantitative results can be seen in Tables 1 and 2 for two videos. The evaluation metrics considered are : Recall, Precision, Average False Alarms Per Frame (FAF), Number of Groundtruth Trajectories (GT), Number of Mostly Tracked Trajectories, Number of Fragments (Frag), Number of Identity Switches (IDS), Multiple Object Tracking Accuracy (MOTA) and Multiple Object Tracking Precision (MOTP).
This work has been submitted to CVPR' 14.
| Method | MOTA | MOTP | Detector |
| [59] (450-750) | 56.8 | 79.6 | HOG |
| Ours (450-750) | 53.5 | 69.1 | HOG |
| Method | Recall | Precision | FAF | GT | MT | Frag | IDS |
| [77] | 96.9 | 94.1 | 0.36 | 19 | 18 | 15 | 22 |
| Ours | 95.4 | 93.4 | 0.28 | 19 | 18 | 42 | 13 |
Video Representation We continued our work from the previous year on Fiber-Based Video Representation. During this year we focused on obtaining competitive results with the state-of-the-art (Figure 13 ).
|




The usefulness of our novel representation is demonstrated by a simple video inpainting task. Here a user input of only 7 clicks is required to remove the dancing girl disturbing the news reporter (Figure 14 ).
|
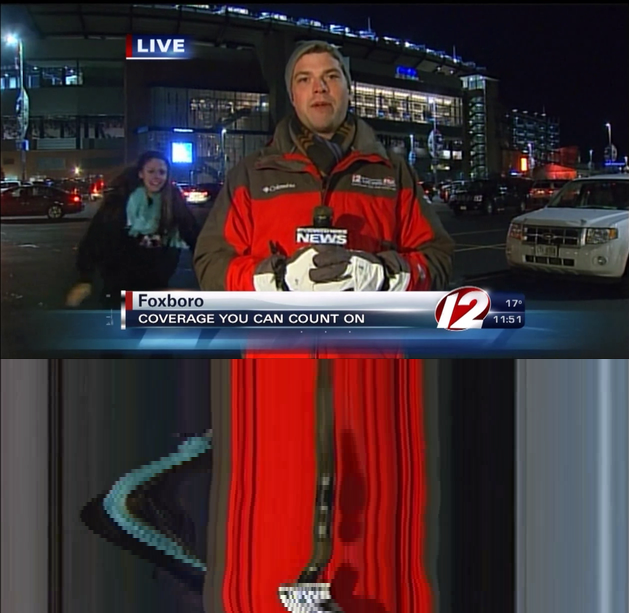
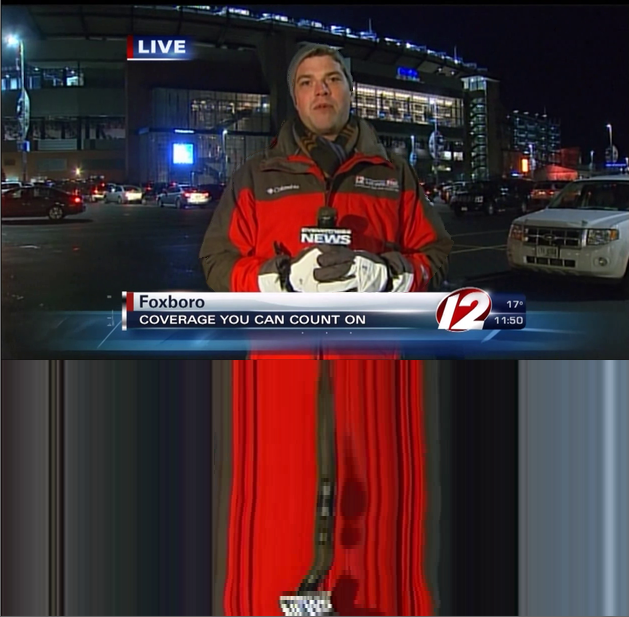
This work has been accepted for publication next year [41] .